

This post belongs to a series called AI for humanists. The previous post introduced general terminology (such as AI, LLMs, etc). This one is about a specific technology called embeddings and also a brief critique of humanism. We will be talking about the following concepts:
- Token
- Vector
- Matrix
- Tensor
- Embedding
- Transformer
- Attention
The models that are getting all the media attention fall under the umbrella of Generative AI. However, all of them depend on another technology called embeddings. I find that a general understanding of embeddings is more important than knowing the minutiae of transformers. So while we could endlessly go on about relevant terms regarding generative models (hallucination, temperature, etc.), let's turn our focus to embedding models. (Also, at this point there are great explanations of them online, such as How large language models work, a visual intro to transformers by 3Blue1Brown).
For a sentence to be used in machine learning, we first need to tokenize it. Tokens are just parts of words. For example:
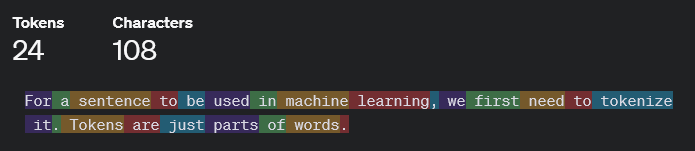
The specifics of this do not matter for our purposes. You can just think of tokens as words. This means the result of tokenization is a list of words.
Word embeddings are the new thing going on in NLP since 2013. They are a way to represent words using numbers. They encode not only words (syntax) but also meaning (semantics). If you want to get the meaning of a whole sentence, you can literally just calculate the mean of all the words in the sentence. Yes, that actually works.
Although both are neural networks, generative models and embedding models are different. ChatGPT, Claude and Gemini are generative models. Their output is generated text (or audio, etc.). Embedding models are less flashy: they have names like text-embedding-3-large and bge-en-icl and all-MiniLM-L6-v2 (see MTEB). You can think of a generative model as having an embedding model inside it. In fact, one of the first transformers (BERT) generated an embedding matrix as a byproduct (Boykis, 2023). Today, however, embedding models are their own separate thing.
Older embedding models (such as word2vec) were not great at ambiguity. While they are able to encode all the different meanings of a word, they have no mechanism to select the appropriate one. This is where transformers come in. Transformers are language models that use a mechanism called attention. It essentially makes the words pay attention to the other words in the sentence. This enables models (both generative and embedding) to take context into consideration - and thus to disambiguate meaning correctly. This is ChatGPT's secret sauce. In fact, "GPT" stands for Generative Pre-trained Transformer (don't worry about pretraining).[1]
For example, in the sentence "I went to the bank to deposit money", the word "bank" is ambiguous. Is it a river bank or a savings bank? The model can use the word "deposit" to understand that it’s a savings bank. These are contextualized embeddings - their word embedding can differ based on their surrounding words. (Sanseviero, 2024)
Generative models take a sentence as input and output another sentence (actually, by now, we have multimodal models which can take different kinds of data as input and output, but the principle is the same). Embedding models take a sentence as an input and output a vector. Vectors cannot be understood by humans, but they can be compared to other vectors, which enables tasks such as classification, clustering and search.
A vector is a list of numbers. One way to interpret a vector is as a location. Remember the Cartesian plane from high school mathematics? The vector (2,3) in a cartesian plane is a point in which "x = 2" and "y = 3" . In this sense, each word in a vocabulary has a location in vector space. This space is not universal; there is not some higher Platonic plane where the words live. Each vector space is relative to each embedding model (and its corresponding vocabulary and training procedure). Each vector space has a dimensionality. OpenAI's old embedding model (text-embedding-ada-002) uses 1536 dimensions.
Vectors can have many dimensions. (1,1,1) is a vector in 3 dimensions; it can, for instance, be used to indicate a location in 3D space in a videogame. It is easy to make vectors with many dimensions - just stick more numbers at the end. They are, of course, harder to make sense of. (Just ask a game developer about quaternions and I guarantee you will get an exasperated sigh).
We can interpret a vector in other ways. One such way is as an arrow that points from the origin of the space ( (0,0) or (0,0,0) or whatever) to the location indicated by the coordinates. In this case, a vector can be thought of as representing a direction. This will make more sense shortly.
The paper for the original embedding model (word2vec) has an interactive demo. The classic example is as follows:
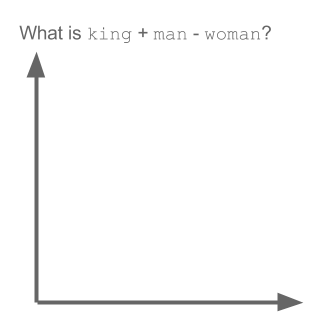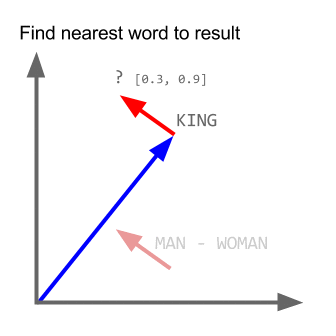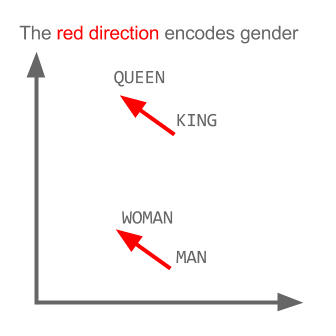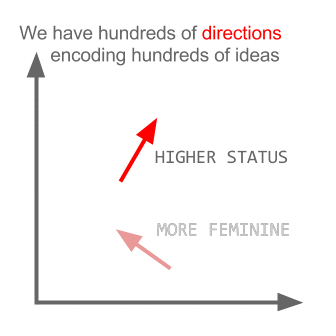
king - man + woman = queen
This is word algebra. If you subtract man from king, you get the direction in space that encodes 'royalty'. If you add woman to royalty, you get queen. This is what "set the natural language community afire in 2013" (Moody). Here is an explanatory gif:
The way these models are trained is simple enough. Every token is initialized as a random vector. During the training, the vectors are moved through space. The training stops when the vectors stabilize. By this measure alone, with enough data, somehow, we get semantics. This is the most perplexing part to me: how we just need the Distributional Hypothesis and nothing else. It sounds too simple. And it is not just me: this result sounds improbable even to the ones who built it.
Somewhat surprisingly, these questions can be answered by performing simple algebraic operations with the vector representation of words ... Finally, we found that when we train high dimensional word vectors on a large amount of data, the resulting vectors can be used to answer very subtle semantic relationships between words (Mikolov et al., 2013, p. 5)
They find that a) you can do word algebra and b) the vectors encode not only words but meaning. This is how we are used to thinking about computers: they can do words, but no meaning. Meaning is social; meaning is human. Computers don't understand the words - for them, they are just numbers.
In fact, I was repeatedly told by my professors that meaning and signification is something fundamentally human and that Numbers and Science and Machines destroy Subjectivity.[2] Technology (derogatory) is opposite to Being (complimentary), and so on. This attitude seems to be confirmed in every single Digital Humanities-adjacent paper I have ever read: the authors are always expecting their peers to have this "humanistic" attitude against technology and feel the need either to justify themselves or to take a combative stance.
Humanism is thus defined not only by its celebration of the fundamentally human but by its derogatory attitude against the non-human. This issue of human exceptionality and the bifurcation of nature (into nature and culture) is extensively explored by contemporary thinkers of science and ecology (Haraway, Latour, Stengers).
Well, guess what. We can bicker forever about "true understanding" and "consciousness" and "creativity". But surely there is something going on. The goalposts need to be moved again, as they often are with AI.
An important missing piece for current-day computers is the ability to make analogies. ... Analogy-making is the ability to perceive abstract similarity between two things in the face of superficial differences. This ability pervades almost every aspect of what we call intelligence. (Mitchell, 2009, p. 204)
While Mitchell is not particularly impressed by LLMs since they can't pass some simple tests, something has changed since 2009. Transformer-based models can do analogies that were previously impossible. How far this actually goes is an open problem, but I think this warrants some optimism. In fact, I believe this pessimism comes from an unwarranted belief in cognitivism. After some decades of mainstream attention, cognitivists seem to feel threatened by the sheer usefulness of the behaviourist premises of...
I did not sign up for a philosophy lecture
Sure. I was getting off track. Let's go back to the subject at hand. This is science and math and stuff. So what can we do with embeddings?
Word embeddings are a straightforward way to analyse bias in language. This blog post (cited by Bolukbasi et al, 2016) shows a word2vec model trained on a dataset (or corpus) of teacher recommendations. Their findings are enlightening.

Women are described using words like kindergarten, menopause, feminazi, maternal, bubbly and compassionate. Men are described using words like egotistic, arrogant, pathetic, dorky, humble and likeable. In another part of the article, they find that the model learned that atheist is the masculine opposite of feminist and that philosophy is the masculine opposite of sociology. Regarding all this, they conclude:
Students have a far more elaborate vocabulary to criticize women for being "unprofessorial" than to criticize men.
Here comes another magical part. They show us how to use vector rejection to remove gender from language. It is simple in principle. You find the gender direction in vector space by subtracting words like he and she. You remove this direction from all words in the vocabulary. Bolukbasi et al. even manage to do this while maintaining the gendered meaning of words they regard as non-ideological (such as grandfather-grandmother). This can be used, for instance, to reduce bias in automated systems which make decisions (think health insurance, mortgages, law, etc).
I hope this is enough to argue that this kind of word math, instead of "the reduction of rich experience to mere numbers" (Schimdt), can be useful in promoting subjectivity instead of destroying it. As Hester suggests in Xenofeminism, instead of rejecting Technology as a tool of domination (as is much too common in the humanities), we can both retrofit tools of domination for our own purposes and, by understanding the technology, build our own tools for our own purposes. But this means having some mastery of technology ourselves instead of denouncing it as fundamentally corrupt. This is how we can aspire for a cyborg psychoanalysis.
Okay, but now for real. Enough of this. You care about products. About business. About making money.
Recommendation engines

Stitch Fix is a personal styling company. Their business is recommending clothes. They have embeddings of their clothes, which they can query.
Our customer recently became pregnant, so let’s try and find something likeitem_3469but along thepregnantdimension ... The first two are items have prominent black & white stripes likeitem_3469but have the added property that they’re great maternity-wear. The last item changes the pattern away from stripes but is still a loose blouse that’s great for an expectant mother. (Moody)
Much like the case with king - man + woman = queen, by combining the vector for pregnant with the vector for the item the client likes, they can search for items which are similar to both. Something like: pregnant - person + item = ? should get these results.
Since this was made in 2015, I have no idea how it works. Today, you have multimodal models that can generate embeddings for both words and images. This means you can search for images using words. Here's a tool for searching for faucets with similar vibes. I still find it hard to believe that this works at all.
Simon Willinson used this to build a simple recommendation engine for his blog. He encoded every post as a vector and calculated their similarity. At the end of every post, he recommends the post which is most semantically similar to the one the user just read. Neat!
Retrieval augmented generation
The most common use case for embedding models today is retrieval augmented generation (RAG). If you want to use AI to help with some kind of research, this is probably how you do it.
Instead of reading through a whole book (which might be hundreds of pages long), you can ask an AI to tell you what's in there. The problem is that the AI does not have access to that book. If you ask anyway, it is likely that the AI will hallucinate - that is, say stuff that sounds correct but is actually wrong. Since LLMs are prone to hallucinating, we use semantic search to give the LLM a factual basis for its generation.
Every single "talk to your pdfs ✨" application uses this technique. They segment your document in chunks and create vectors of those chunks. When you ask a question, they turn your question into a vector and run a similarity comparison between every chunk vector and the question vectors. The result is the most semantically similar chunks of text. They are sent to an LLM, which gives you a summary of the result.
One way to look at it is that you are giving the AI the book for it to search through so that it won't simply come up with stuff just to please you. The image here is of an eager intern to whom you are assigning some reading. Another way to think of this is that you are searching the document by semantics instead of syntax (ctrl + F), and the LLM is just a thin layer on top of the semantic search to help improve the user's experience. I find the latter to be more useful.[3]
Now that you know how RAG works, you can probably spot a potential source of issues. It uses your question's semantics to search for similar chunks in the text. But what if you ask something like "give me a summary of the document", or "how many times does X appear in the text"? These questions require knowledge of the whole document, and the RAG system only gives the LLM little parts of it. The result is as follows: it is going to encode that sentence, and it is going to return a bunch of trash to the LLM, and the LLM will try its best to make something of it. That is, it will probably hallucinate something because it does not have enough information to answer your query. This will either generate a nonsensical response or (worse) it will be completely understandable and completely wrong, and you probably won't notice.
I have seen this happen. This is a source of confusion that you should be aware of. This is called AI literacy - knowing how to use your tools. Sometimes ChatGPT searches the internet for answers, and sometimes it doesn't. Sometimes it uses RAG on a document you sent, and sometimes it doesn't. Sometimes it runs code and analyses your data using software, and sometimes it hallucinates the analysis completely. At this point, every corporate product on the face of the Earth has some kind of 'AI integration'. Some of them will implement fixes for these issues and some won't. Since the whole point of AI is for it to feel magic ✨, you need to take care and know your tools.
That's it for this post in AI for humanists. Next time we will be getting into hyperdimensional spaces. Spooky.
Footnotes
- You can pre-train general foundation models which can then be fine-tuned for a specific task. It costs millions of dollars to pre-train a large model, but only a fraction of that to fine-tune one. This is important because it enables the sharing of models online. If you want a model that classifies images of cats, you don't have to train one from scratch; you can just download a large model and fine-tune it with relatively few images of cats. ↩︎
- "Science forecloses the subject" is an aphorism every Lacanian is familiar with. It was also never uttered by Lacan (Beer), although that is beside the point. The point, as I understand it, is that it is an obvious thought-terminating cliché (Montell). ↩︎
- In fact, the LLM part of RAG can be dropped altogether and substituted for an interface that better fits your task. LLMs just happen to be good all-around flexible interfaces (and, more importantly, they enable you to call your product AI). ↩︎